经典搜索算法:DFS和BFS
深度优先搜索和广度优先搜索是两种基本的搜索算法,正如搜索的意思而言,算法本身没有任何的智能或者简略,只是单纯的寻找。类比一个实际的例子,当你去上计算机导论这门课程的时候,你知道的只有教室的名称,因此,最基本的办法就是去一个个教室去看,直到找到你的目标教室,当所有教室都被找过的时候,还没有找到你的教室,这就是你对整个教学楼的教室进行了一次遍历,而DFS和BFS就是这样的策略,二者唯一区别在于你是先看完一层楼再看下一层,还是先看完每层楼楼梯口的教室再看每层楼离楼梯口远一点点的教室。一定要记得,是先构建出了教学楼,然后再去教学楼内搜索。这就是这两种方法的直观理解,接下来,从算法层次去讲解这两种搜索策略。
前导知识
这篇博客写的基础是,C/C++编程基础和基本数据结构的掌握,具体是结构体和结构体的操作、数组、队列和栈的表示方法及其代表的数或者图、指针及其表示的链表等,当然还涉及到了C++模板库的使用(STL),具体是队列和栈的实现(当然,也可以自己写一个队列和栈的结构体和相应操作)。
图/树的保存
一个典型的模型抽象过程,是将一种相互连接和便利的结构表示成图或者树,通常情况下,我们对图的搜索称为图的遍历,对树的搜索就叫搜索,这二者都有相应的BFS和DFS过程,而且没有区别,因此在这里不区分遍历和搜索,统一称为搜索,同时因为树其实本质上是一种特殊的图,因此后续的讲解也从图的角度来讲,换成树本质也一样。
既然是搜索图或者搜索树,那么我们必须想办法去表示这样的图/树,这里我们介绍两种表示方法,一是邻接矩阵,适合节点少,边密集的情况;二是邻接表,适合节点多,但是边并不密集的情况。
一些典型术语:一个图通常用G(V, E)来表示,V表示顶点集合(vertex),E表示每条边的集合(Edge),通常节点数量用N表示,边的数量用K表示。
邻接矩阵
邻接矩阵是指用一个矩阵来表示一个图,即对于一个有N个节点的图,我们建立一个N×N的矩阵,每个元素a[i][j]表示节点i到节点j是否连通或者边的代价(长度,衡量节点之间的远近)是多少,对于无向图a[i][j]=a[j][i],对于有向图二者可能并不相等,我们这里用无向无距离的图来距离,即每条边的长度都相等,不存在代价,且只要边存在,从左到右或者从右到左都可以。
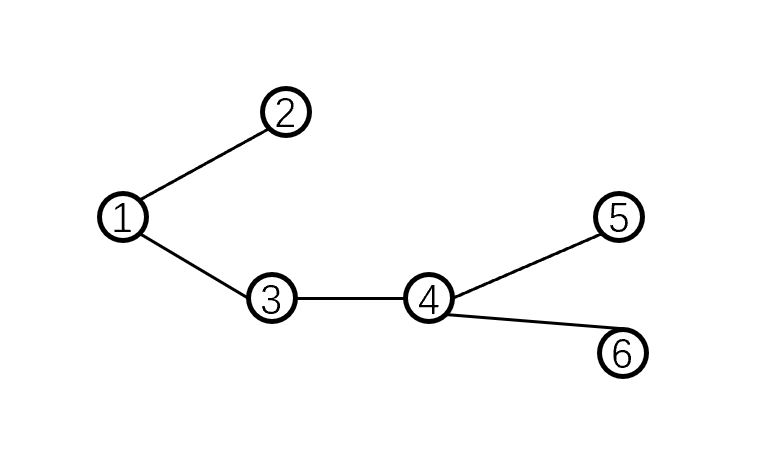
例如我们上面这个简单的图(其实可以看得出来这也是一个树,画风勿喷,手画的),用邻接矩阵来表示就是一个6×6的数组,其中的每个值为:
$$
0 1 1 0 0 0
$$
$$
1 0 0 0 0 0
$$
$$
1 0 0 1 0 0
$$
$$
0 0 1 0 1 1
$$
$$
0 0 0 1 0 0
$$
$$
0 0 0 1 0 0
$$
第i行表示第i个节点和谁连接,第j列表示谁能到达第j个节点(有向图内),当然对于无向图,这就是一个对称矩阵,不存在行列的区分。
这就是邻接矩阵,非常简单的表示方法,唯一缺点在于,节点数特别多,但是边特别少时,矩阵是一个非常稀疏的矩阵,效率太低,因此就有了我们后面的邻接表。
邻接表
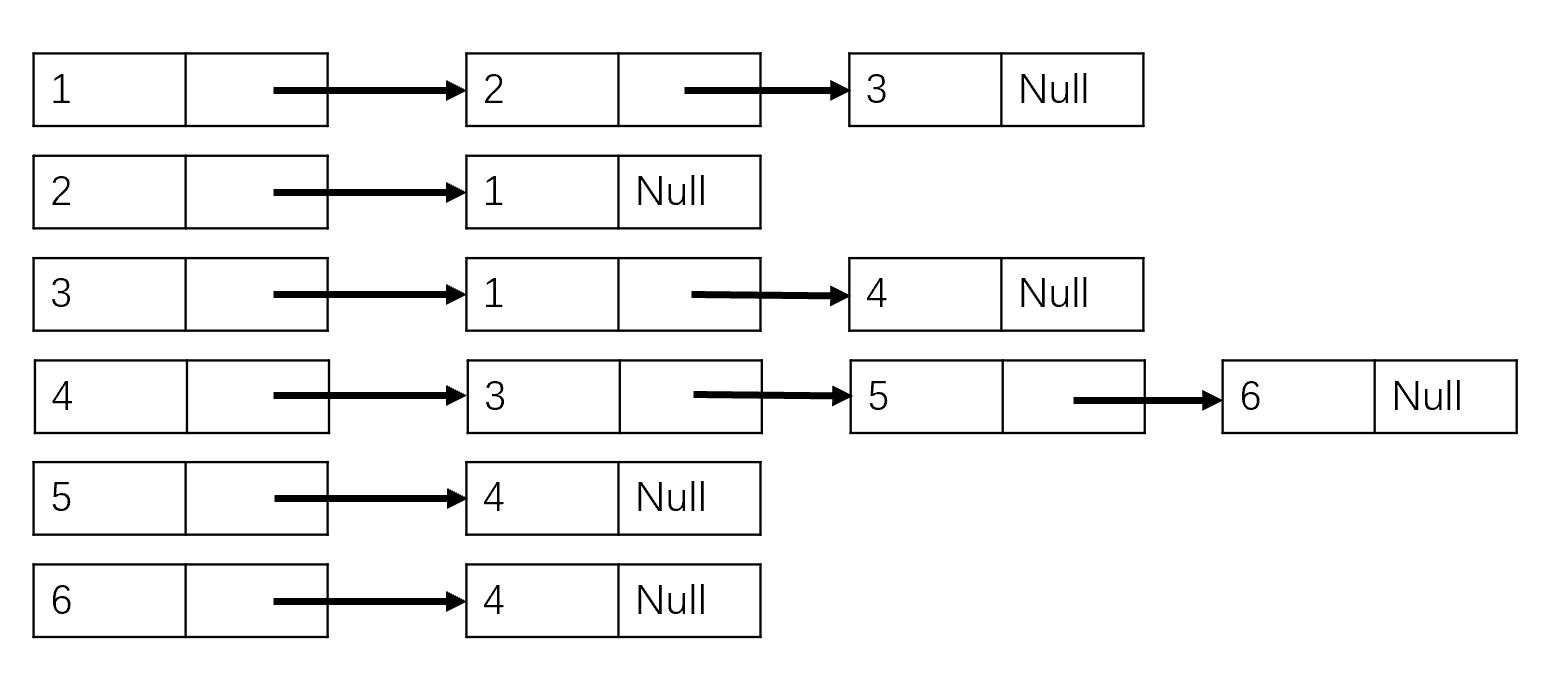
邻接表也非常简单,上面的邻接矩阵我们利用点的关系来表示图,邻接表则是利用边的关系来表示图,这样在节点多的情况下,可以节省内存。
对于N个节点的图,表示方法就是,建立N个链表,第i个链表中的元素表示与第i个节点相连的节点,每个链表元素的结构体如下:

同样,我们表示了上述图的结构为:
DFS
DFS,深度优先搜索,顾名思义,就是首先往深搜索,即搜索到这一分支的最深节点(树的叶子节点,图的终止节点/没有后继/后继全都访问结束)。因为是深度优先,所以利用栈/递归的结构来实现。算法过程是:
//栈的实现过程
初始节点入栈;
while(栈非空):
弹出栈顶节点,并标记为已访问;
该节点的后继节点如果未访问,就入栈;
如果找到节点,跳出循环;//递归的实现过程
function dfs(节点i)
{
标记i已访问;
如果找到节点,return;
for (所有i的后继节点j且j未访问)
dfs(j);
}上述两种方法都是差不多的,如果没有找到节点的条件,那么算法会一直执行,直到所有节点都被访问。
BFS
BFS,广度优先搜索,顾名思义,就是先把每层的元素访问完,然后访问下一层的元素。实现也比较简单,利用队列实现:
初始节点入队;
while(队非空):
弹出队首节点,并标记为已访问;
该节点的后继节点如果未访问,就入队;
如果找到节点,跳出循环;简单来说,就是每次都把下一层的节点依次填入队列,这样从队首出来的节点依次就是每个节点所连接的元素,利用队列先入先出的特性,因为肯定是层数更浅的节点先入队列,因此先出的也是层数更浅的节点,这样就可以实现按照层数来依次遍历所有节点的效果。
实现代码
实现代码直接百度,会有一堆,笔记本省11%的电量了,来不及写上面我说的过程,但是谷歌或者百度应该是很好找到这两个算法的实现的,可以自己先找一下。
后记
其实正如我开头说的,DFS和BFS都是一种搜索方法,还是用那个例子来说,你想要在教学楼找到你的教室,那一般我们会逐层寻找(如果我们把楼层看成深度的画,就是BFS),但是我们不会每个教室都去看,如果看到教室号是增加的,同时目前的号已经大于要找的教室,那我们就不会在这一层浪费时间,这在算法上叫做剪枝,感兴趣的可以继续搜索看看。同样DFS也有实例,例如在走迷宫时,我们一般会把每条能走的路标记出来,依次每条路走到底,看哪条路能走到终点还是死路,才会换另一条道路尝试。当然所有DFS和BFS都可以相互转换,唯一区别在于解决问题的复杂性不同,所以灵活分析,是寻找教室还是走迷宫,再选择算法非常重要!
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以其他方式联系。
 辽ICP备19018266号
©2020 SadAngel
辽ICP备19018266号
©2020 SadAngel

