Part-Activated Deep Reinforcement
Part-Activated Deep Reinforcement Learning for Action Prediction
阅读笔记
先放上论文链接:Part-Activated Deep Reinforcement Learning for Action Prediction.
总述
本文是一篇ECCV2018的一篇行为预测的论文,主体是融合强化学习(RL)和骨骼检测算法,利用强化学习和骨骼结构过滤无效的背景噪声,从而保留动则相关的成分,精度上得到了很大提高,是一种视频(而非图片)的动作预测。
行为预测的难点在于空间和时序信息的综合利用和实现,目前已有的算法主要是两类:一是利用相关特征进行样本匹配,二是分类模型。显然,前者缺少足够样本,鲁棒性太差,而后者则是主要利用了时序信息,预测准确率和捕捉到的动作帧数正相关。这些方法的共同点在于缺少了人类本身的肢体信息,这些方法的卷积包含了各个图像的背景和其他动作无关因素,这些噪声都影响了动作预测的准确率。PA-DRL从这个角度出发,主要目标是为了提取动作预测相关因素,过滤无关噪声。
算法
出发点

如上图所示,PA-DRL的核心思想在于当我们能选择出动作相关特征(上图下面部分的结果)时,我们就能获得更准确的动作方向,从而预测也就可以更加准确。
局部特征提取和表达
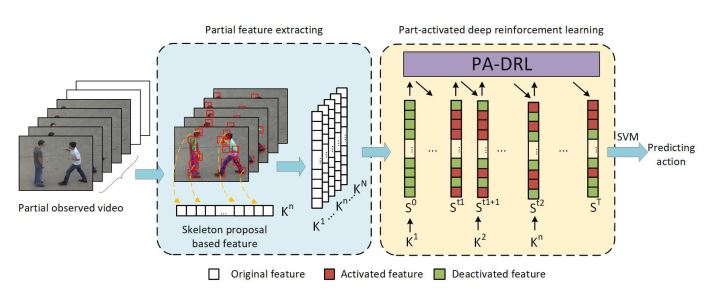
特征提取的部分其实很简单,简单来说,两部分:一是基于骨骼的图像提取关节和周围的明显信息,二是依次级联(concatenating)这些图片,保证了人体结构信息的特征。
这里定义了一些变量和函数:
$\varGamma(·)$ 用来指代特征的级联,论文里没有写细节,他们的代码也没有开源,我的理解就是特征向量的串联起来就行。
$N$表示当前视频中观测到的帧数。
$p$表示每一帧中人的索引,人的总数记为$P$。
$\{S_1, S_2, …, S_p, …, S_P\}$表示每个人的骨骼(skeletons)集合
$\{J_{S_p,1}, J_{S_p,2}, …, J_{S_p,e}, …, J_{S_p,E}\}$就可以表示一个拥有$E$个关节的骨骼
$F_{J_{p,e}}^n$表示基于骨骼的关节提取到的特征
因此对于第n帧的图片来说,特征的级联结果为:
$$K^n=\varGamma_{p\in P}(\varGamma_{e\in E}(F_{J_{p,e}}^n))=\varGamma_{u\in U}(F_{J_u}^n)$$
这样级联的好处主要有两点:一是保留了每个人的结构信息,二是保留了时序上的逐帧信息。
PA-DRL部分
这一部分是利用强化学习过滤动作无关关节的部分,如果大家对强化学习有所了解的话,就明白RL基本上是一个马尔可夫决策过程,其核心就是评价每个状态的价值,通过学习找到每个状态的价值,学习的数据源就是和环境交互产生的$(S_t, a_t, S_{t+1}, Reward)$,具体的强化学习部分不是这里的重点,因此不在此叙述,这里主要讲PA-DRL中这几大基础要素的设计。
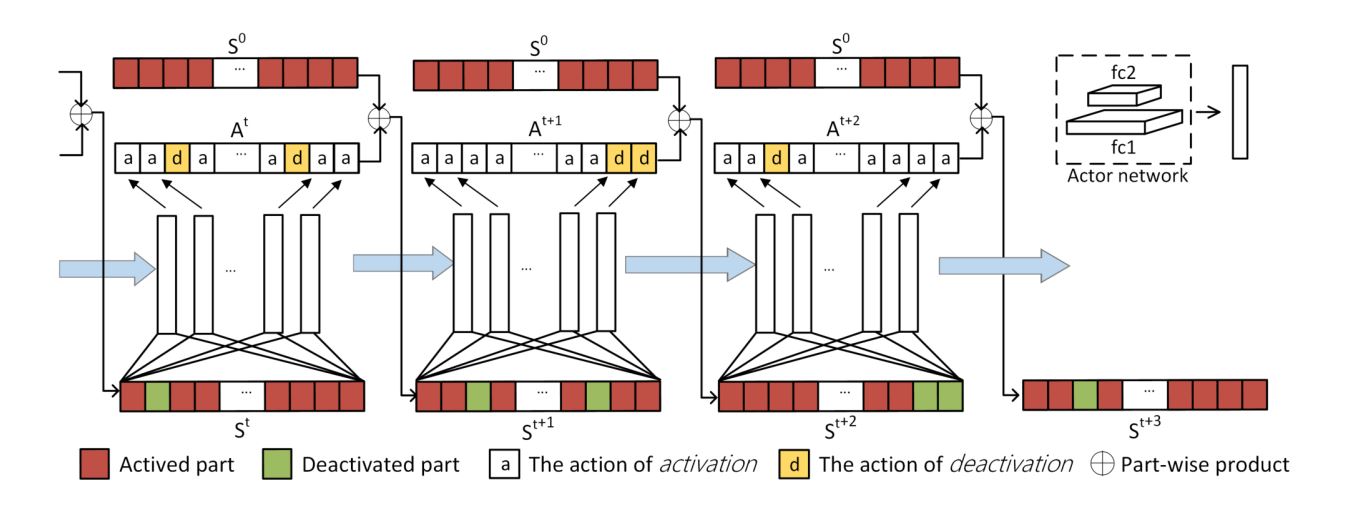
作者将对于每个关节的激活和抑制建模成了Action,而每个关节的激活和一直的状态就是迭代的状态,正如上图所示,我们可以通过$S^0$和上一个动作$A^t$得到下一个状态$S^{t+1}$,这样一个马尔可夫决策过程就产生了。
马尔可夫决策过程产生意味着环境构建成功,接下来就是Reward的设计了,通过环境获得Reward的反馈,RL-agent才能学习到一个有效的策略。
核心的价值函数为:
$$r(A_\omega^t)=\Theta(\eta_\omega^t,\epsilon_\omega)×(|r(A_\omega^{t-1})|+1)$$
$$R(\omega)=\frac{1}{T}\sum_{t\in T}r(A_\omega^t)$$
简单来说,就是预测正确获得一个正的奖励值,错误就没有奖励值(这里他的论文里前面说是负值,后面又统一用0处理,因为没有代码,所以姑且用0叙述)。而预测对的关节数越多,奖励值也随之增大。
值得一提的是,每个关节的动作都是独立的网络得到的,而没有利用一个网络去或者所有关节的动作,避免了关节之间的相互影响。
有了整个环境之后,利用AC框架求解这个问题的最优决策,就产生了一个激活或者抑制的决策,再利用这个决策得到的相关关节特征去预测下一个动作。
总结
总体而言,这篇论文利用了骨骼特征识别和DRL算法过滤了动作预测过程中的无效信息,大幅度提升了动作预测的精度。可惜的是没有开源代码,因此细节就不在这里列出了(论文中有),下次有时间的时候,复现这篇论文再补充细节部分。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以其他方式联系。
 辽ICP备19018266号
©2020 SadAngel
辽ICP备19018266号
©2020 SadAngel

